Git Peaks #1 : Les bases

Un outil pour les gouverner tous
Système d’exploitation, IDE, langage de programmation, navigateur… Les développeurs tiennent beaucoup aux outils qu’ils utilisent dans leur environnement de travail, et ils partent souvent en croisade contre les aficionados d’autres alternatives qu’ils considèrent comme des fanatiques impies, dont nous tentons de sauver l’âme de la perdition éternelle…
Mais s’il est un outil pour les gouverner tous, il s’agit très certainement de Git. Développé en 2005, Git est devenu la solution de versionning de code majoritaire, loin devant ses prédécesseurs comme SVN ou Mercurial. Bien-sûr il existe plusieurs instances Web (Github, Gitlab, Bitbucket…), plusieurs clients graphiques (GitKraken, gitg…) et il est intégré dans la plupart des IDE de façon native. Mais quel que soit notre environnement, dans la grande majorité des projets nous revenons à cet outil devenu central.
La ligne de commande reste l’outil officiel, et permet d’accéder à l’ensemble des fonctionnalités -très étendues- de Git. Elle est pourtant souvent laissée de côté, délaissée pour des outils graphiques permettant d’utiliser Git sans connaître les commandes elles mêmes, masquant souvent le fonctionnement réel de Git.
Maîtriser l’ensemble des innombrables fonctionnalités de la cli git est bien entendu un travail collossal, mais les notions nécessaires pour versionner son code proprement ne sont pas si complexes à appréhender, comme nous allons le voir ! Découvrez les bases de Git, mais tout d’abord, un peu d’histoire…
Git, mékéskécé ?
Git, c’est un outil de versionnement de code, qui a les objectifs suivants :
- Sauver & Restaurer : Sauvegarder son projet régulièrement en créant un historique complet de l’évolution du projet, en permettant de revenir à tout point de l’historique sans perdre son travail.
- Synchroniser & Partager : Synchroniser tout ou une partie des versions du projet, et partager son travail avec ses collaborateurs.
- Bac à sable : Créer à volonté des versions parallèles du projet sans difficulté et sans risque pour son travail ou celui de ses collaborateurs.
Plus exactement, Git est un System de Contrôle de Version (VCS en VO), c’est-à-dire un système qui enregistre les modifications d’un ou plusieurs fichiers à travers le temps afin de pouvoir revenir à une version antérieure spécifique du projet. Il existe plusieurs types de VCS : locaux, centralisés et partagés.
Les systèmes locaux ne permettent de sauvegarder un historique du projet qu’en local. Les désavantages sont bien sûr évidents : en cas de panne de la machine local, il n’existe pas de sauvegarde du projet, et ce système ne gère pas le travail collaboratif.
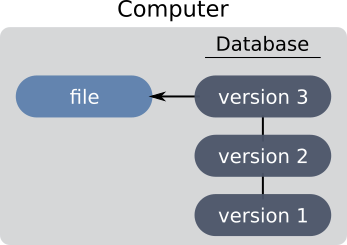
Pour palier aux inconvénients des systèmes locaux, ont vu le jour les VCS centralisés. Cette fois, les développeurs partagent un même serveur qui conserve l’historique. L’utilisateur conserve en local la dernière version du projet. Il peut pousser ses modifications sur le serveur et récupérer celles de ces collaborateurs.
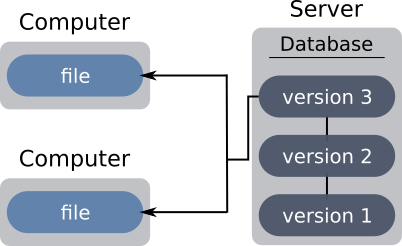
Le problème de la panne reste entier : en cas de coupure d’accès au serveur, les développeurs ne peuvent pas créer de nouvelle sauvegarde (point dans l’historique), et doivent donc stopper leur développement sous peine de perdre la cohérence installée dans le projet. Pire, en cas de perte du serveur, bien que la version courante du projet soit présente sur les postes des développeurs, l’historique lui est perdu.
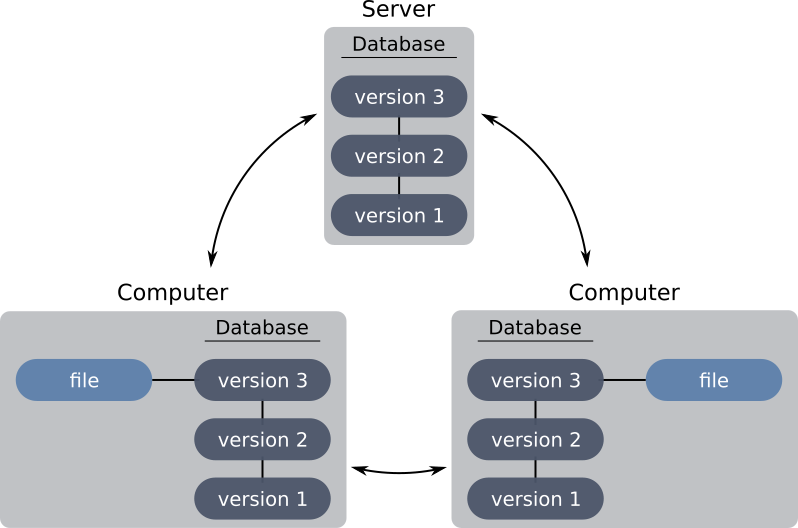
Afin de remédier à cela, le systèmes de contrôle de version distribué (comme Git) proposent une architecture dans laquelle l’historique est non seulement présent sur le serveur, mais aussi sur les machines des développeurs. Plus précisément, chaque nœud peut potentiellement jouer le rôle de serveur, permettant aux développeurs d’envoyer les nouvelles modifications du projet d’une machine à l’autre, sans passer par le serveur.
En pratique, nous privilégions l’utilisation d’un serveur, car cette architecture minimise fortement les risques de perte d’information. » En cas de crash du serveur, les développeurs pourront mettre en place un nouveau serveur et y pousser l’historique présent sur les machines des développeurs.
En 2005, BitKeeper, jusque lors CVS utilisé pour versionner le code du noyau Linux, devient payant. Les développeur du noyau Linux décident alors de créer Git, qui prendra rapidement la première place des outils de versionning. Git est développé dans l’idée d’être rapide, simple, complètement distribué.
La ligne de commande Git, pourquoi ?
Il existe une panoplie d’interfaces graphiques à Git. Que ce soit les interfaces web (Github, Gitlab) ou les interfaces locales, elles permettent de s’affranchir (du moins en partie) de l’utilisation de la ligne de commande Git. En effet, les gens perçoivent souvent celle-ci comme étant trop complexe et incompréhensible. Elle reste cependant la seule interface qui permette de maîtriser réellement la gestion de son repository, donc du code. Et le code, dans les métiers de l’IT, est la partie vitale du projet. L’utilisation d’une interface graphique sans connaissance préalable de la ligne de commande est souvent commode, « tant que tout se passe bien ». Mais à la première difficulté il devient difficile de régler le problème graphiquement. On en revient la plupart du temps, avec l’aide d’internet, à une suite de commandes Git obscures pour nous sortir de ce mauvais pas…
Bien-sûr, maîtriser entièrement la ligne de commande Git demande des années d’expérience. Git est en effet un outil très complet.
Les bases de Git
Les bases de Git pour démarrer
Git est un système de versionning de code distribué. Nous poussons donc notre code sur un ou plusieurs serveur. Pour ce faire, Git se doit de nous identifier et de nous authentifier. La première partie se faire en configurant nos noms et emails comme ceci. Attention ! L’adresse email renseignée doit correspondre à celle renseignée sur le serveur Web (Github, Gitlab…).
$ git config --global user.name "My Name" $ git config --global user.email "my_email@peaks.fr"
L’authentification peut elle se faire de deux manière : en https ou en ssh. Cela dépend de l’adresse utilisée pour cloner le repository (en `https://` ou en `git@`). L’authentification avec https demande un login/password, tandis que l’authentification avec ssh utilise la clé id_rsa par défaut (généralement dans `.ssh`).
Pour aller un peu plus loin, on peut également définir l’éditeur de message de commit par défaut
$ git config --global core.editor nano
Note : nano à l’avantage d’être disponible sous linux et MacOS, et par défaut avec Git Bash sous windows
Ensuite, il suffit de cloner le projet grâce à son adresse.
Nous avons maintenant notre version locale du projet, prête pour le développement !
Sauvegarder son travail, les bases de Git
La base de Git est le commit, point de sauvegarde du projet. Lorsque l’on est satisfait des modifications faites sur le projet, on peut valider les modifications que l’on veut ajouter au point de sauvegarde (`git add`) et ensuite créer le point de sauvegarde (`git commit`). Les commandes sont les suivantes :
# modifications des fichiers $ git add$ git commit -m'message de commit explicite'
Le message de commit est très important, lorsque l’on regardera l’historique des modifications du projet, ce sera le point de référence pour comprendre les modifications liées au commit.
Le nouveau commit apparaît maintenant dans la liste des commits, visible avec git log.
On peut ensuite continuer à travailler, en sachant que quoi qu’il arrive, il sera toujours possible de revenir à ce point précis du projet. Lorsque l’utilisateur est à nouveau satisfait de son travail, je crée un nouveau commit, faisant ainsi avancer l’historique de son projet.
Partager son travail
Git un outil avant tout local. Les modifications ne sont partagées que lorsque l’utilisateur utilise des commandes le demandant explicitement. Pour envoyer son travail sur le serveur, il faut avant toute chose récupérer les modifications faites par les collaborateurs, puis envoyer ses propres modifications. Ceci donne :
#Récupérer les modifications distantes et les ajouter en local $ git pull #Envoyer les modifications locales sur le serveur $ git push
Et voilà ! Avec 4 commandes de base (`git add, commit, pull et push`), vous pouvez déjà sauvegarder votre travail avec Git et le partager avec vos collaborateurs !


