KubeCon

Like every year in the spring, what I'm looking forward to is not the arrival of sunny days but KubeCon in Europe. Last year in video from my sofa, it's face-to-face this time! So here I am on my way to the sunny beaches of Valencia in Spain for a week of tapas and a good dose of Kubernetes.

KubeCon, what is it?
KubeCon is mainly an opportunity for me to discuss the open source projects that I use on a daily basis and to meet their maintainers and contributors.
In these exchanges I was able to discover the Pixie project, an observability tool (https://github.com/pixie-io/pixie), talk a bit about the future of infrastructure as code by chatting with representatives of the Pulumi and Crossplane projects (https://github.com/crossplane/crossplane) and exchange more widely with other enthusiasts of Kubernetes and CNCF projects.
The Argo community (https://argoproj.github.io/), in particular ArgoCD, a GitOps continuous delivery tool whose strengths I can only praise, made an impression by filling an entire amphitheater for the exchange session with the main maintainers of the project.
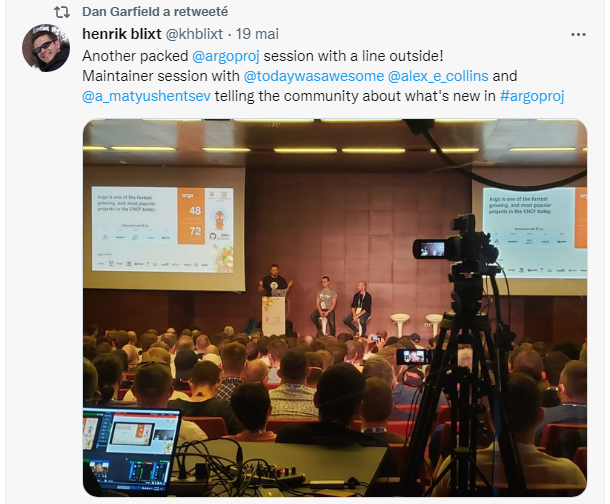
Today KubeCon attracts more than 7 people in person and CNCF projects have become essential in companies. Projects like prometheus, gRPC are not even to present.
It's no surprise that today at the KubeCon keynote, companies that in the past talked about open source like the devil are now major players both as users and contributors. It's a small victory to see Mercedes-Benz and Boeing coming to thank the community on the KubeCon main stage.
However, there is still a long way to go on the issues of open source funding and the time granted to developers to contribute to these open source projects at the center of the solutions sold by these large groups.
The most anticipated KubeCon conference
One of the most anticipated conferences each year is the conference carried out by CERN on the particle accelerator and their massive use of Kubernetes clusters on-premise and in the Google cloud with figures to make your head spin, several thousand pods, 70 TB of dataset to analyze for each experiment. (For those who have not yet seen a classic that dates from KubeCon 2019 while waiting for those of 2022: https://www.youtube.com/watch?v=CTfp2woVEkA).
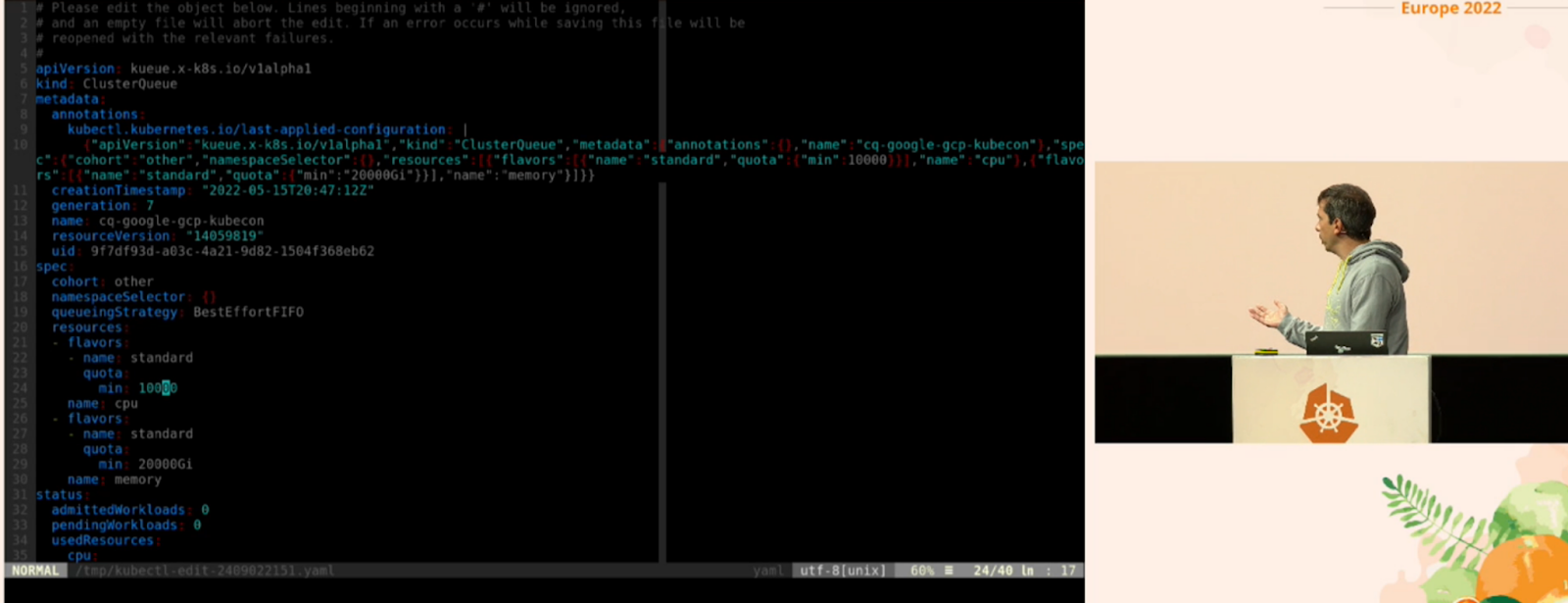
A small ClusterQueue of 20TB of memory and 10k cpu for a demo, who says better?
Over the releases Kubernetes has become very mature and stability is at the heart of all discussions. This often results in fewer new features, fewer "flashy" features. Nevertheless this kubecon allowed me to discover SIG Batch and SIG kueue (https://github.com/kubernetes-sigs/kube-batch, https://github.com/kubernetes-sigs/kueue) who want to bring together projects and initiatives to allow adding in Kubernetes the means to launch application tasks as opposed to services all the time available.
We are not talking about CronJob but rather a complete system for launching tasks with queue management, priorities, quotas and of course scheduling.
Yes, of course you finally have a queuing system in Kubernetes. No more RabbitMQs to maintain just to have a way to pop jobs. Open source projects like Kubeflow and Volcano references in this area already use kube-batch.
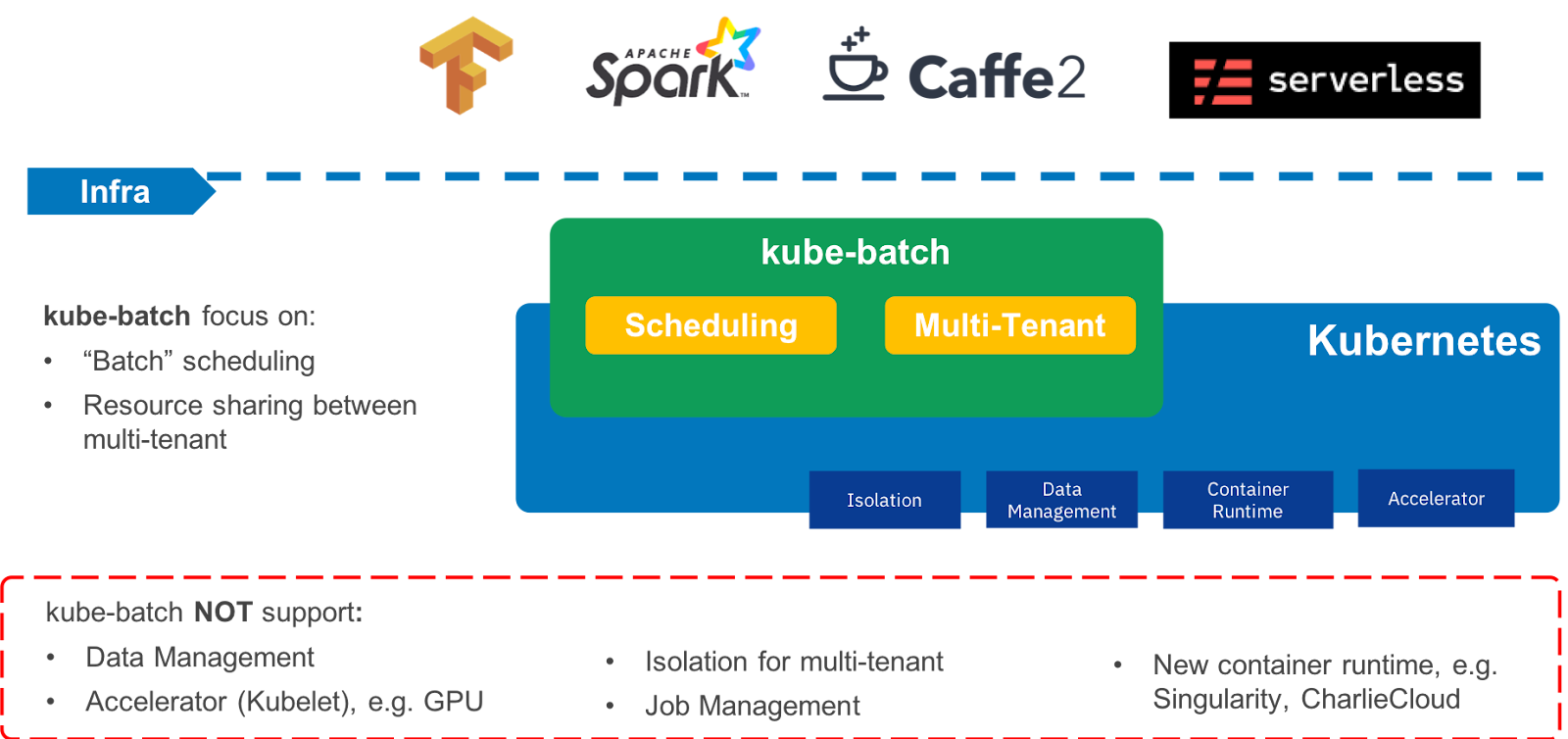
A brief overview of the actors present at KubeCon
Amidst all these booths and conferences, a pleasant surprise is the weak presence of Openshift in favor of open source distributions closer to Kubernetes like Rancher.
Canonical introduced MicroK8s (https://microk8s.io/) with clusters in ARM formed by several Raspberry Pi.
The VmWare monster came with their Tanzu solution to provide companies with a complete environment and above all the famous support so dear to large companies. Undoubtedly Tanzu will impose itself among large accounts as the solution for Kubernetes in parallel with the already well-known solutions of public clouds.
Personally I have never hung on to solutions adding an overlay to an already well-stocked solution. I understand the approach of wanting to reduce complexity and promote adoption, but my passion for Kubernetes, like many, was born by manipulating kubectl, trying to understand these complex mechanisms.
It is by understanding in detail how Kubernetes works that I have made a lot of progress on the software architecture because Kubernetes is ultimately a management application like an application that you develop.
The appearance of nodeless
This KubeCon also saw the appearance of “nodeless”, behind this very commercial name, like all “****less” designations, there is a desire to delegate the management of a computer resource more than a real disappearance by magic. After the “serverless”, here is the “nodeless” which is the delegation of the creation of the nodes of a Kubernetes cluster to a third-party solution.
We used aws-autoscaler for a long time, but today AWS is pushing its open source project Karpenter (https://karpenter.sh/) allowing to manage the creation of the nodes of the cluster according to the needs at a given moment.
The nodes are no longer linked to the stiffness of the group nodes (same characteristics within the same group). Karpenter picks spot or on-demand from the instances offered by AWS to better meet the needs of your cluster.
More turnkey solutions for managing the nodes of your cluster like Cast.ia uses artificial intelligence to deduce the behaviors and needs of your clusters by trying to anticipate the provisioning of the nodes.
Beyond putting AI everywhere, their business model of getting paid on the gains made by their customers using their product is a refreshing sight in the subscription SAAS ecosystem.
The strong presence of security-related topics
The security-related topics discussed last year around OPAs, supply chain and SBOMs have become very mature and are now present in many products and solutions on the market. The CNCF ecosystem is still impressive in its ability and speed to absorb new things to the point of making them commonplace in a single year.
telecommunications giants
Without making an exhaustive list of what I have seen, this year was also marked by the presence of telecommunications companies such as the giant Huawei for their interest in Kubernetes at edge and their contribution to many open source projects.
I was surprised to see such a large representation of solutions allowing to deport the workload closer to industries outside datacenters with solutions around Kubernetes and “cluster suitcases” to perform on-premise-on -premise, direct from the factory!
Some negative points
In the negative points, the return of the movement aiming to install databases in Kubernetes clusters and all that ensues on the stateful, the management of storage and backups. This mode is driven by the maturity of Kubernetes on the stateful and performance needs by bringing the database closer to application containers but also a huge cost saving with respect to the managed offer of public clouds.
But today, hot, I still see this return as a regression. Despite a significant cost, managed databases offer maintenance and scalability comfort that was very difficult to obtain in the past. As often after a KubeCon, we leave with lots of ideas in our heads and projects to test, such as Yugabyte (https://download.yugabyte.com/cloud#k8s-operator) to possibly change your mind about the basics in Kubernetes.
En conclusion
This event remains an unmissable moment for anyone passionate about open source and the CNCF ecosystem, I learned and discovered a lot during this week. For those who were unable to make the trip, you will have the opportunity to see the conferences in the coming days on the CNCF Youtube channel (https://www.youtube.com/c/cloudnativefdn).
Hoping to have made you want to take an interest in CNCF projects and the pleasure of sharing my feedback with you or meeting you in person next year in Amsterdam for the next KubeCon in Europe from April 17 to 21, 2023.
Damien, DevOps @Peaks


